
How to restore websites from the Web Archive - archive.org. Part 3
Choosing “BEFORE” limit when restoring websites from web archive
Last time we spoke about how to prepare a domain for restoring and how to open indexing through robots.txt. Today you will learn how to choose the date of a fully functional version of the old site from web archive.
When domain expires, domain provider or hoster’s parking page may appear. When entering such a page, the Internet Archive will save it as fully operational one, displaying the relevant information on the calendar. If you restore a website from the calendar by such a date, then instead of a normal page will see that mentioned parking page. How can I avoid such a problem and find out the working date of all website pages in order to restore it?
Instructions for choosing date using the example of the Trimastera.ru domain
Enter domain on the main page and then we get a web archive calendar.
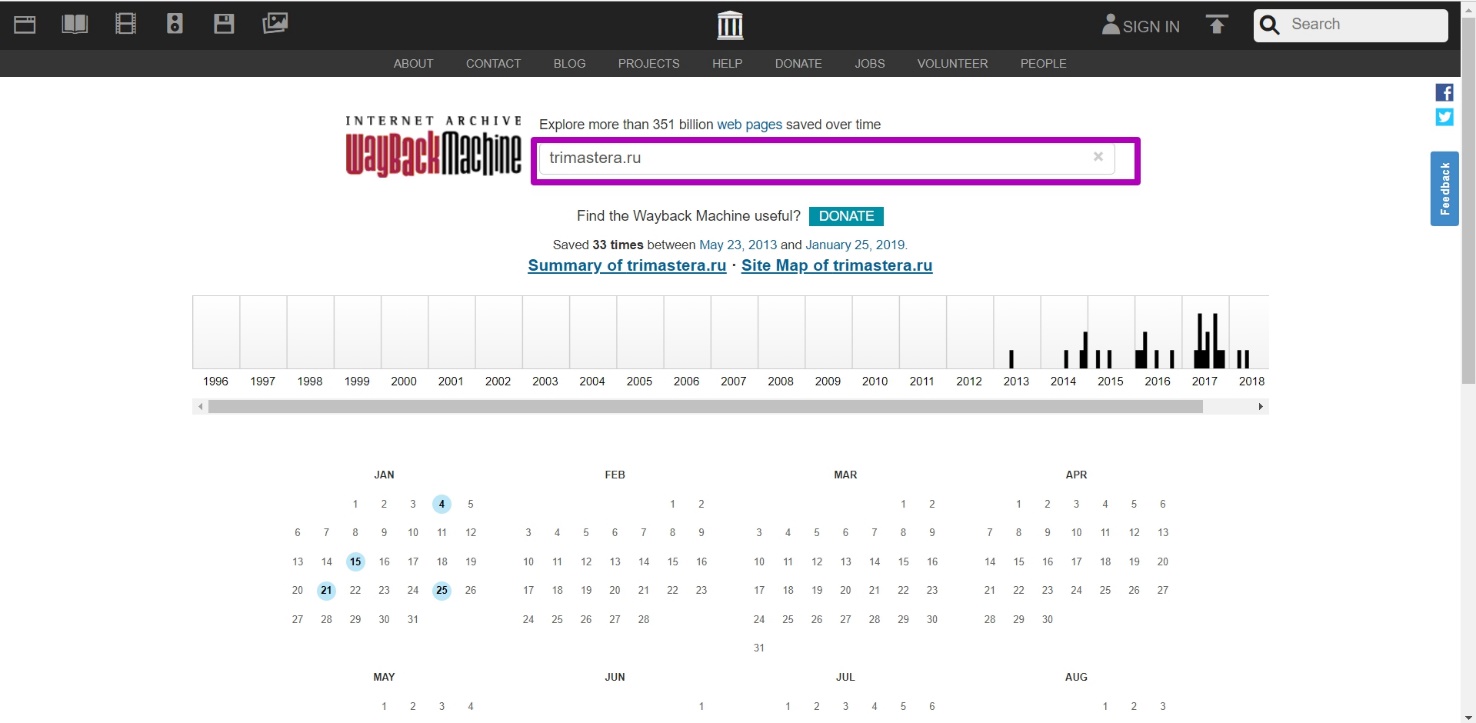
Then we are looking for the latest working version, which will be marked in blue. Open it and see how it looks, if it’s a domain registrar parking page, go on searching. Find the time when the content was archived.
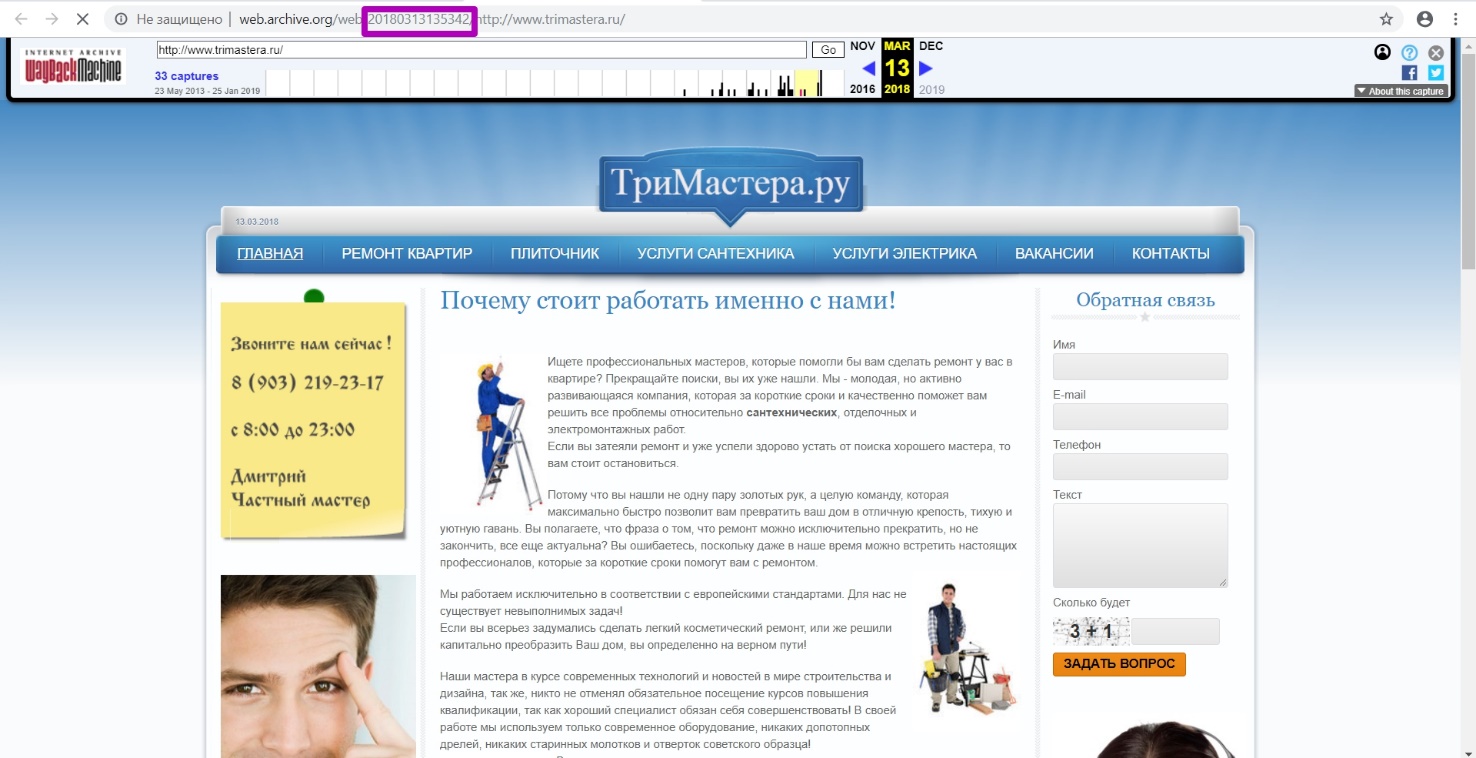
Attention, the timestamp that we see on the link is the date and time of saving only the html-code of this page, but not the CSS styles, images or scripts. All these items have their own save dates, sometimes significantly different from the html file date. In order for the web archive to completely save the page with all its elements, it needs some time. Starting with the page code, all elements are stored with a delay of several seconds to several days, and sometimes even more. Therefore, if you enter this particular timestamp as “from” date of the domain, only part of the page will be restored.
Then go to the DevTools tool to determine where all the elements of the site are loaded from. To do this, press ctrl+shift+i or F12 at the same time in your browser. We see a source code analysis tool.
Go to Network tab, uncheck persist logs. Press F5 or refresh the page.
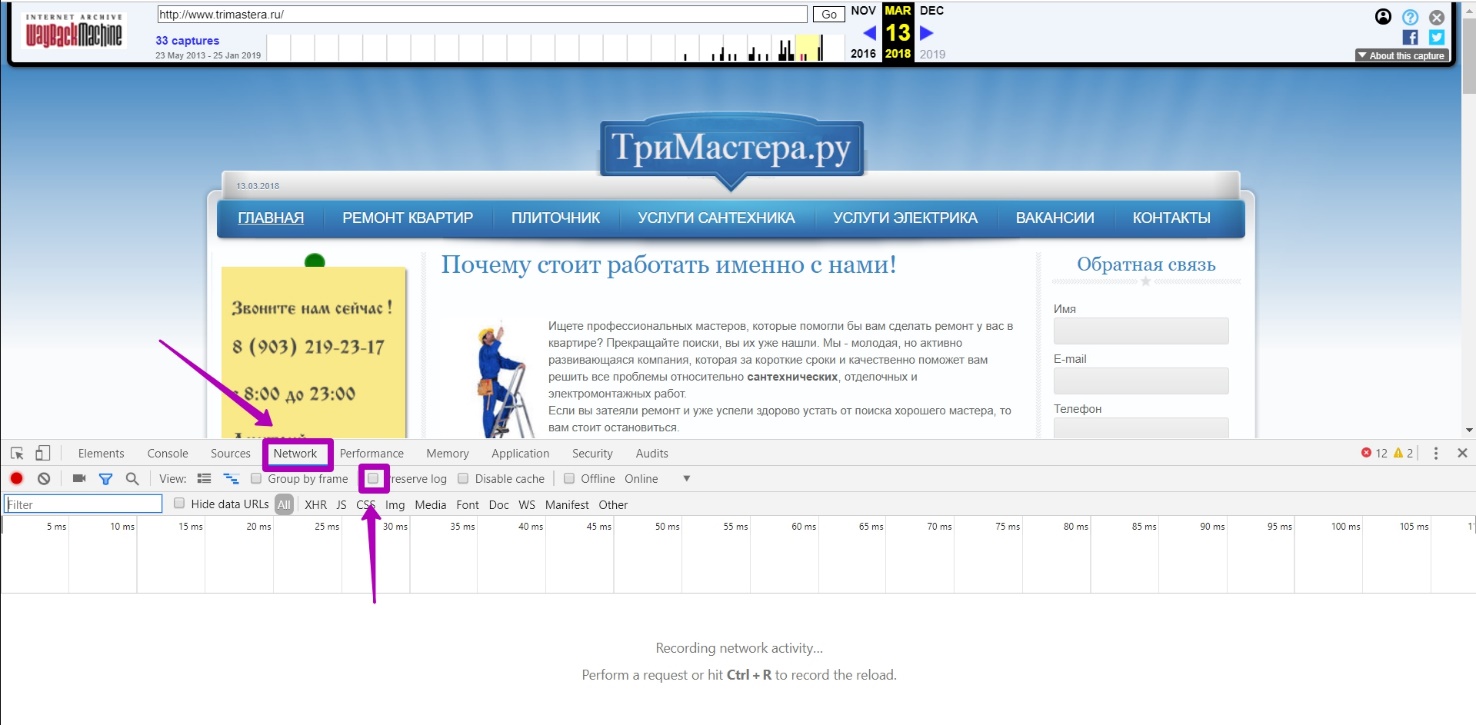
Enter the desired domain Trimastera.ru in the filter field. For general understanding, the filter, even when partially entering the domain name, will display information, and everything that will be written with a space is determined by the tool as an additional filter to the search.
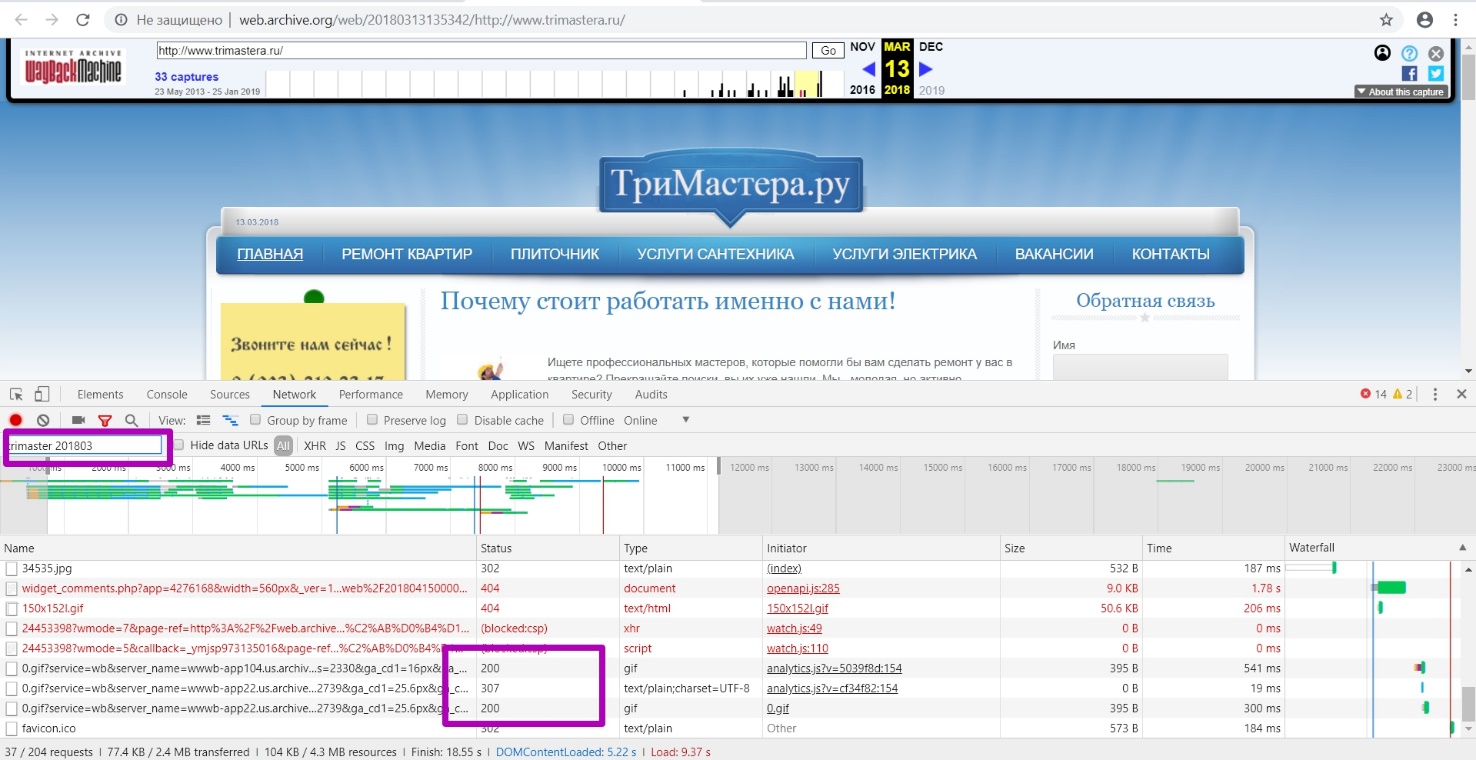
It means that when entering simultaneously the domain name Trimastera and 201803 (as the year and month of the last saving of the website working version based on the correct "blue" date on the calendar) we will get all the links (without external styles, images and other external resources).
Using the example of this domain, we see a lot of urls with 302 response code, since web archive assigned the same timestamp to the elements on the page, but when entering this element itself, web archive redirects to original timestamp.
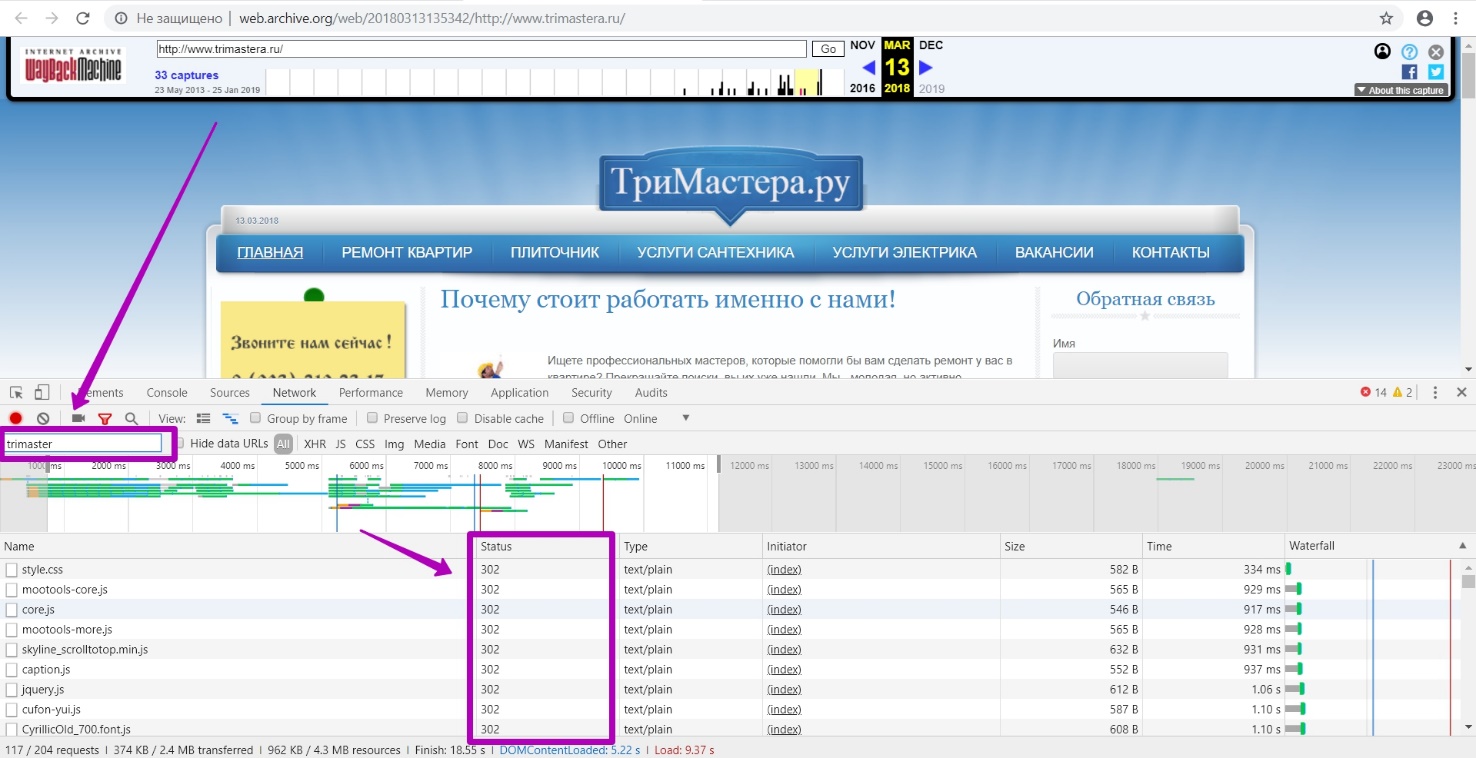
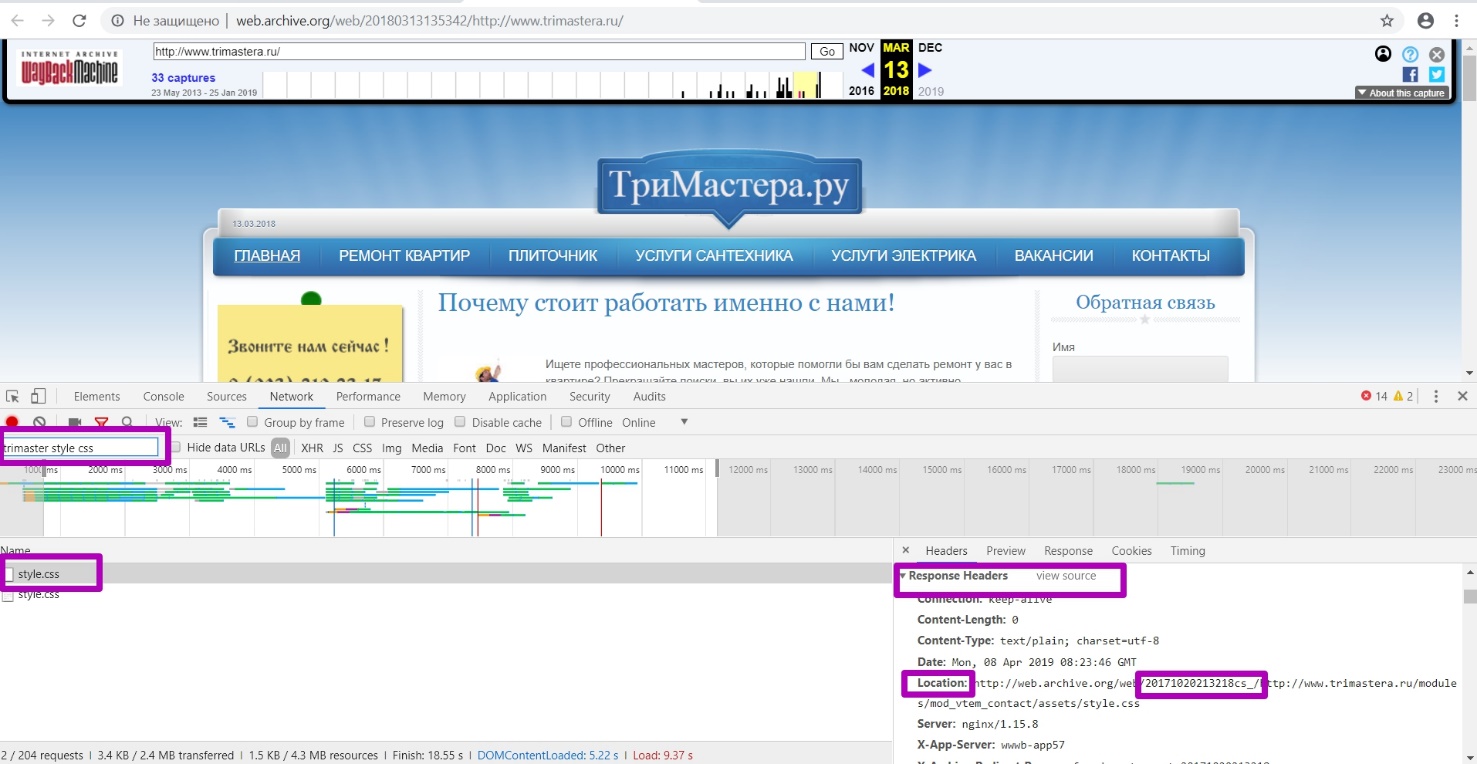
Let's take a look at the page with styles.css styles. The main timestamp is displayed the same as the whole website page, but when we go to the style location page (url of the style itself), we see another timestamp of this particular element.
Let’s change alternately the date 201803 in the search to a larger or smaller one to determine whether there were workable pages during this period, i.e. with 200 response code. Thus, we confirm that March 2018 is the last period of the website working indexing.
You can specify a wider period of time, for example, only a year in the filter field. But when setting such a “to” date, web archive will consider the version for the last second of 2018, and at that moment, as we see, website didn’t work. Specifying a more accurate period up to seconds may not capture individual media or text elements indexed later.
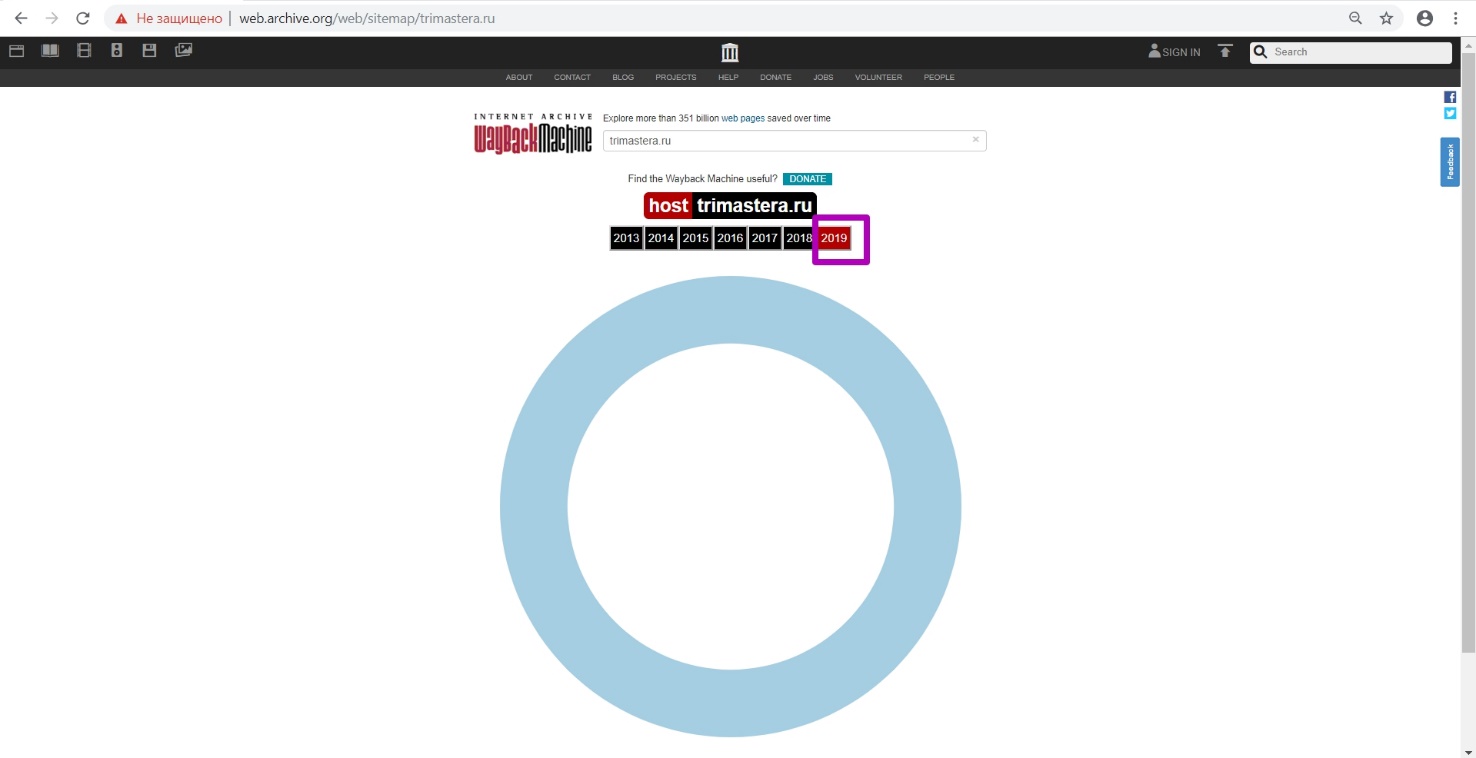
Now we open Site Map tool. We see that for 2019 we do not have website internal pages.
Let’s open 2018, now we see that the website structure is displayed, which means that website has been indexed.
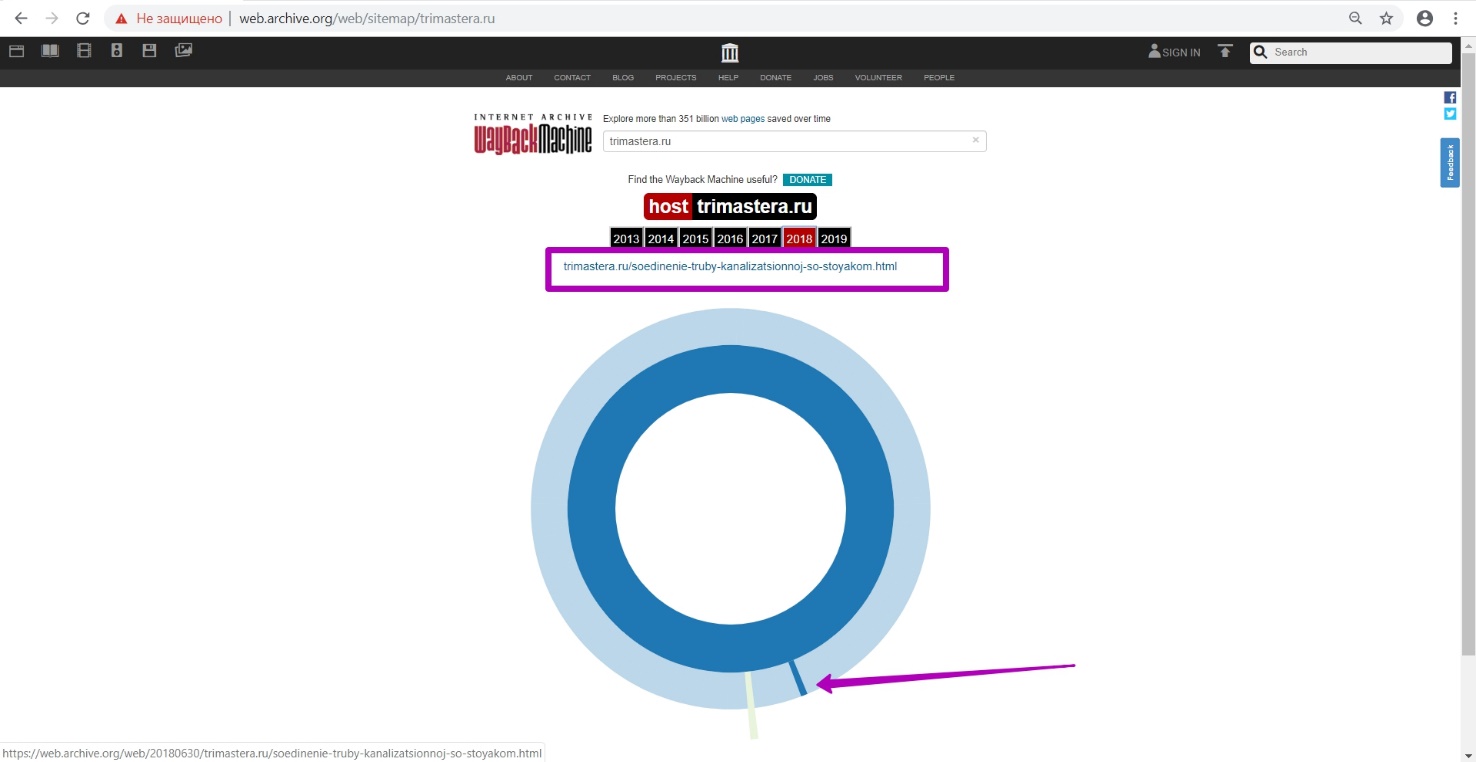
We selectively look through some pages in new tabs for 2018. As we see, timestamp of such pages was recorded on March 15, although at different time. Thus, we check the month of the last working pages.
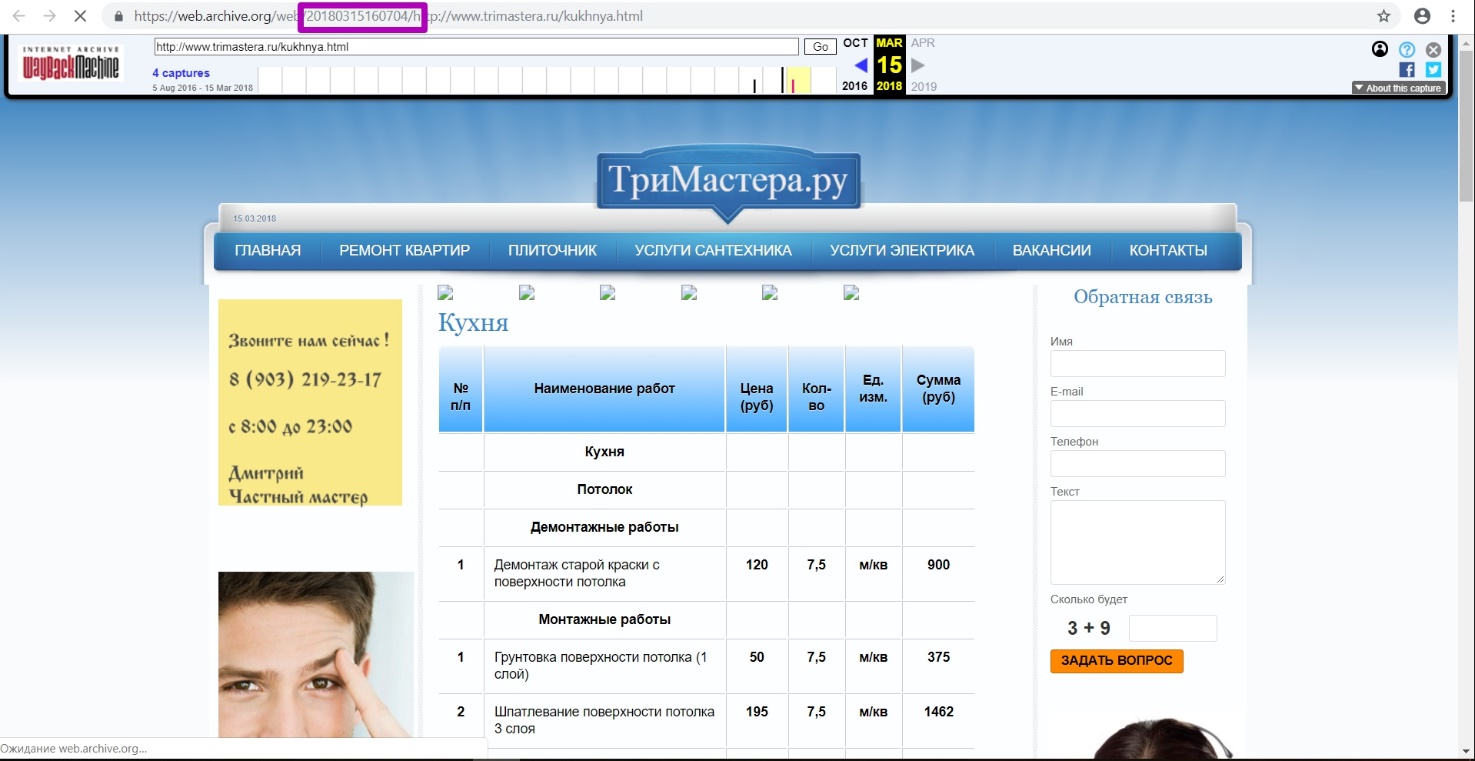
Then open Summary tool for the year 2018 that we’ve chosen before. Check the New URLs column in the table. For the period of 2018, new links were not indexed, which means that at the time of restoration we will download the latest website version from web archive.
Open Explore tool. We analyze url output in a table. If domain was prepared correctly by specifying robots.txt file, we will see a table with all the links for this year.
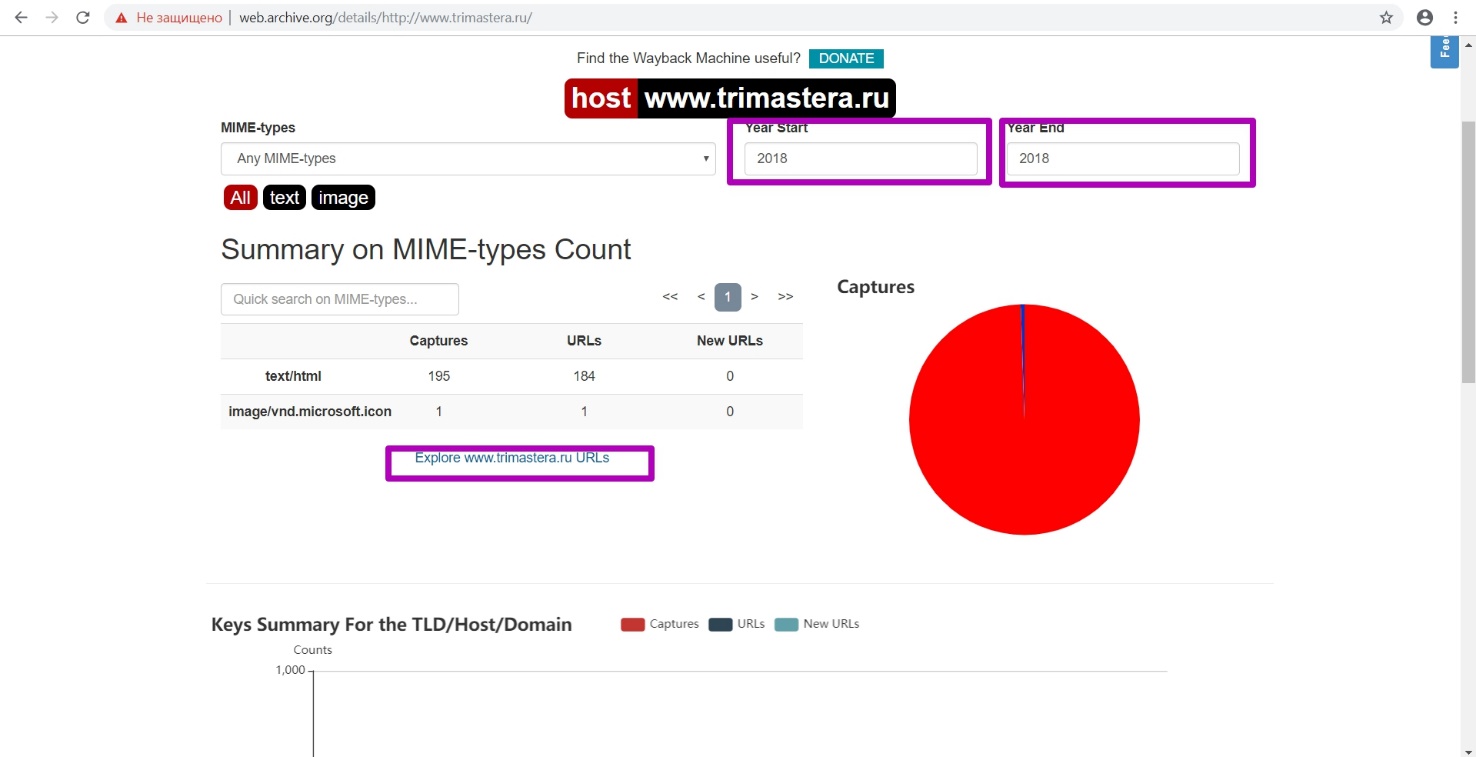
Let's test the hypothesis that the robots.txt file closes indexing. We look at all versions of the robots.txt document in the calendar, and we see that on July 13, 2018 the site was closed.
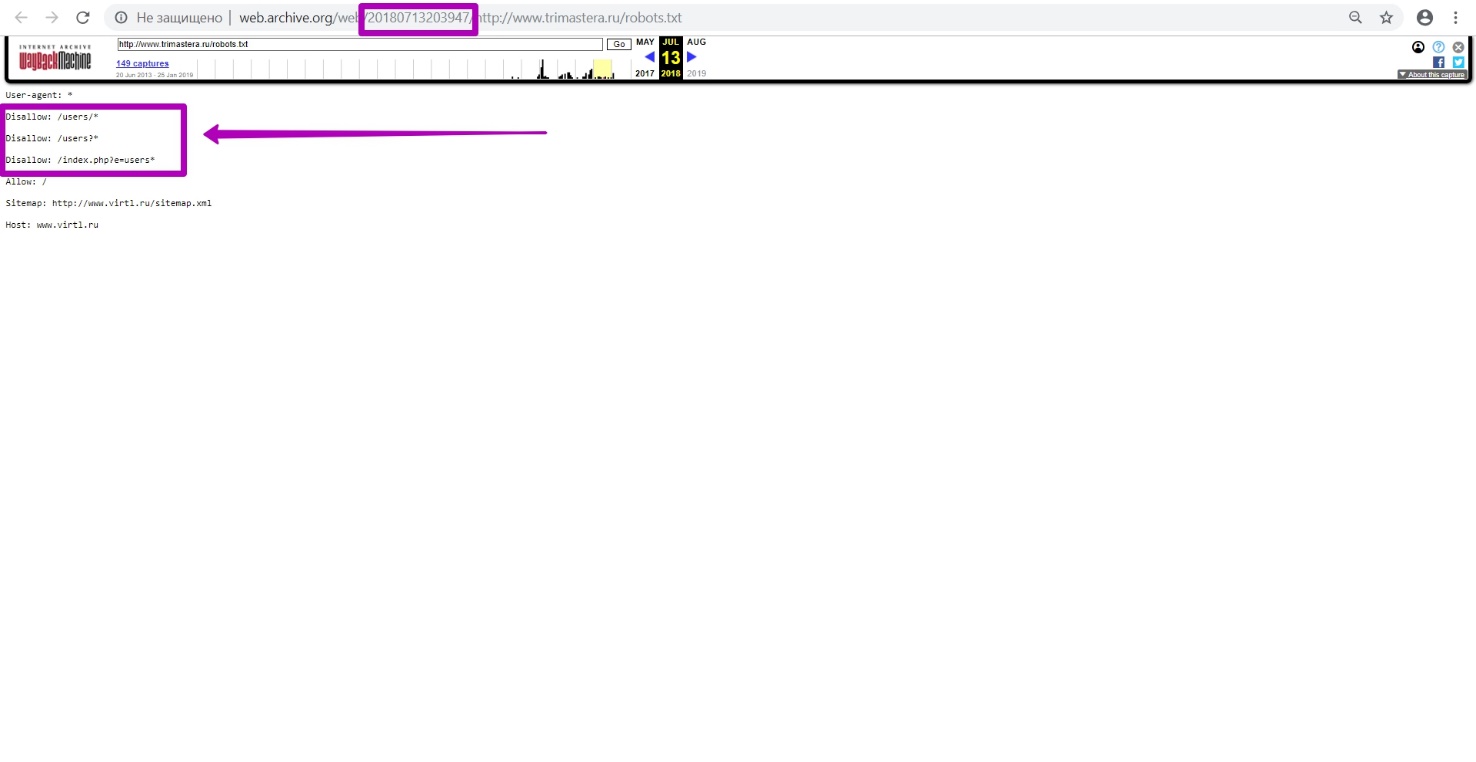
If you have faced with such a situation, you need to prepare your domain by uploading a new robots.txt file, which we described in the last guide.
After robots.txt file successful preparation by using Explore tool, we sort all the links for the year that we are interested in by the “to” date so that the most recent ones are at the top. We are interested only in those links that do not have a redirect, parking pages, or other external elements (not related to the website contents). The latest date of the last url will be the date of last indexing (saving) of the current version of website materials.
Analysis by the Explore tool, as well as work with the “to” date of the domain as a whole, should be carried out 24-72 hours after uploading new robots.txt file, as we remember, in order for the web archive to correctly index all website elements.
In our example we cannot sort the files in the web archive, since there was no uploading a new robots.txt file on the new domain and hosting.
Difficulties when searching “to” date
Example: mastersila.ru website
We go through the same steps as in the previous example:
On the website’s save calendar we look for the “blue” saving date (in our case, December 4, 2016), then check for the absence of a redirect and other errors. On the saved page version go to the DevTools tool (F12 and update through F5). In the same way, enter a part of the domain and date that is greater than the considered one (2017). Since there are no links with 200 response code for the selected period, the last website’s performance was recorded in 2016.
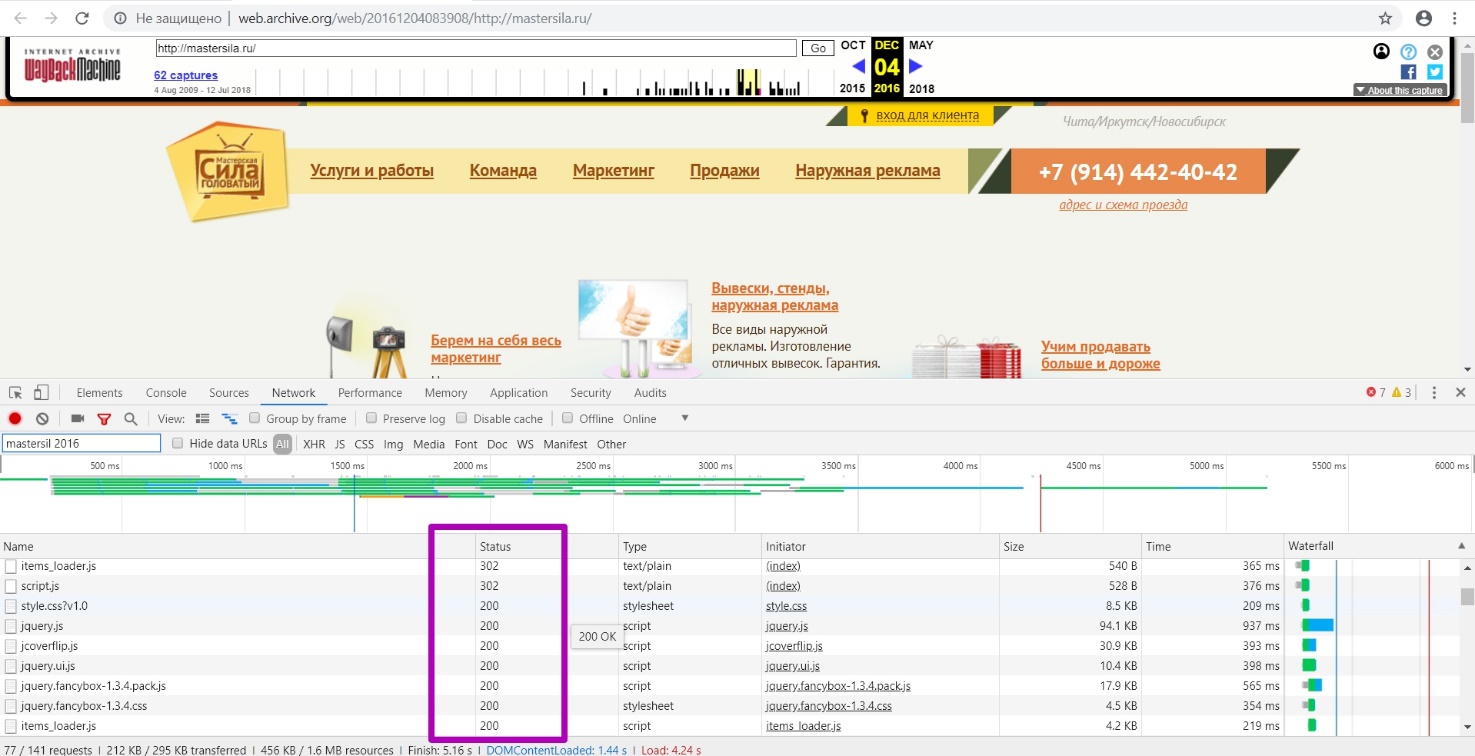
Open Site Map tool and let’s check this hypothesis. In most cases, the last year of the structure display will be the last year of the website’s performance.
As we see, 2016 is the last year of website saving, which confirms our assumption. Working structure is displayed exactly for this period. Go to Summary tool. Let’s see the results in the New URLs section for the period of 2016. As you can see, 39 unique links were generated during this period, which means that this year the site was last time functioning with the current pages versions.
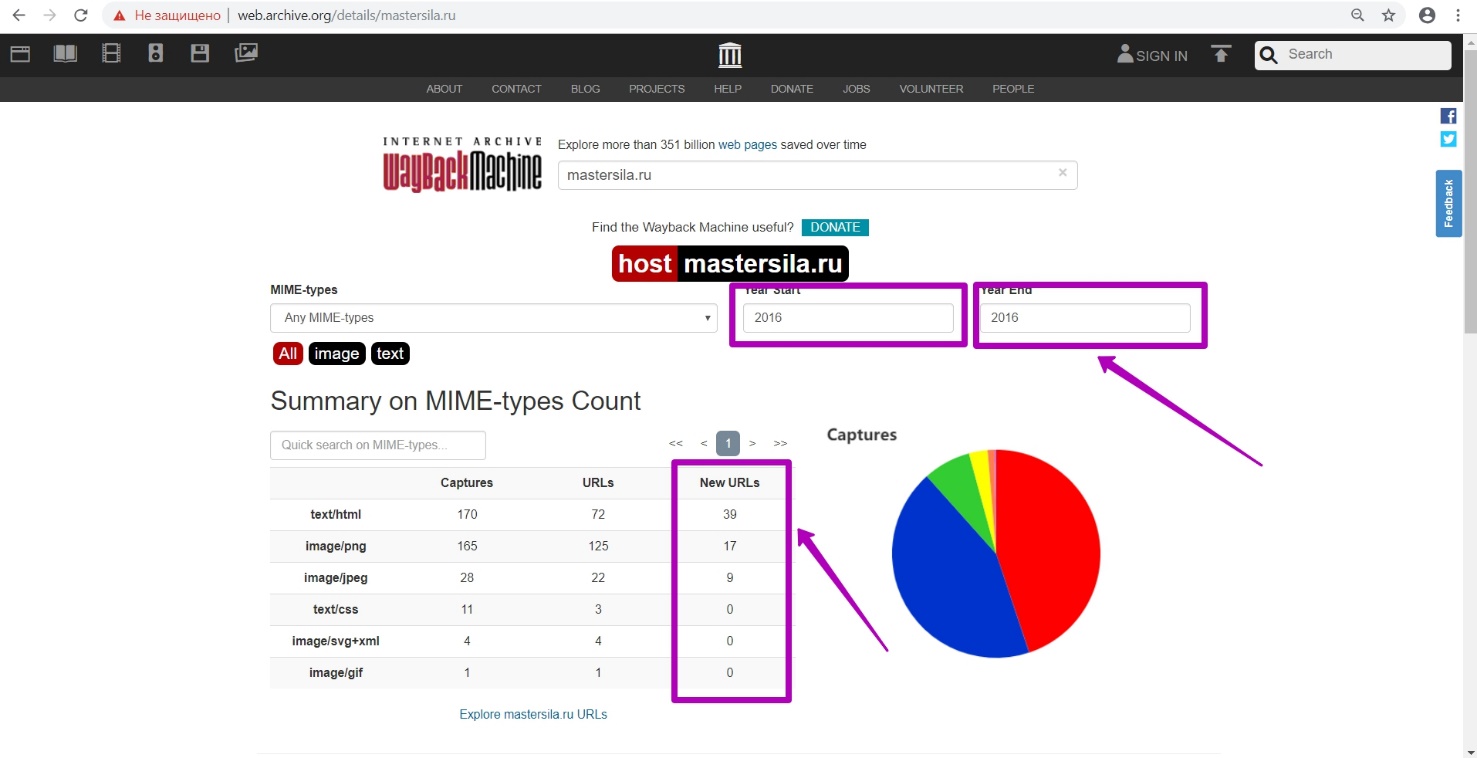
Open Explore tool. Since we have results table, website site is open for indexing, which means that robots.txt file doesn’t block access to bots. Sort the results from the last. Check links for operability, excluding those with redirects and errors. For 2018, all links are redirected. For 2017, new materials are displayed, indexed on March 3.
Let’s check links and then we see that these are redirect pages. So, they should not be considered as working pages necessary for being restored.
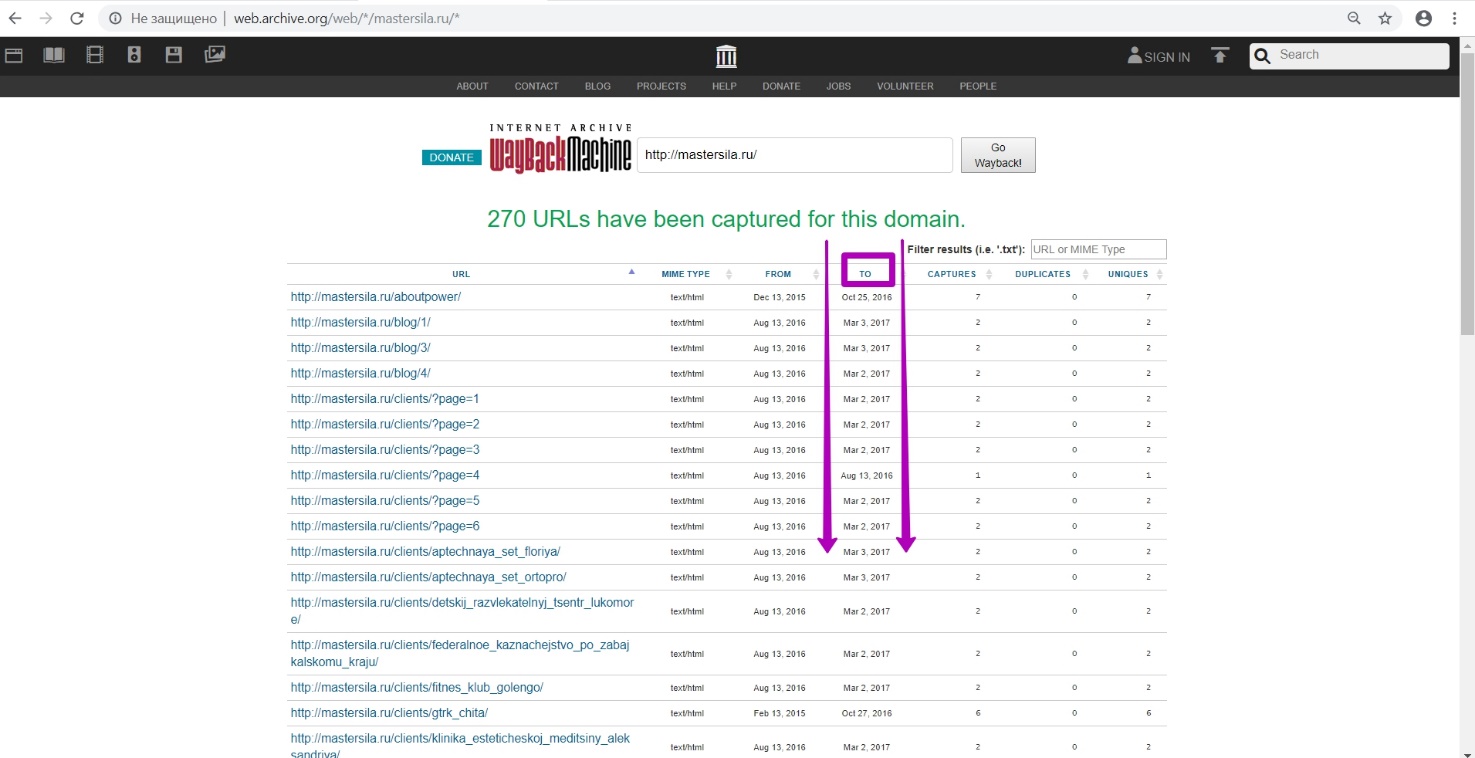
Check links for 2016. We confirm the hypothesis that December 2016 is our “to” date for this domain, since the links are working.
Example: Gkvolga.ru website
As in previous examples, we look at the website latest version for 2018. We see that website was working in 2015.
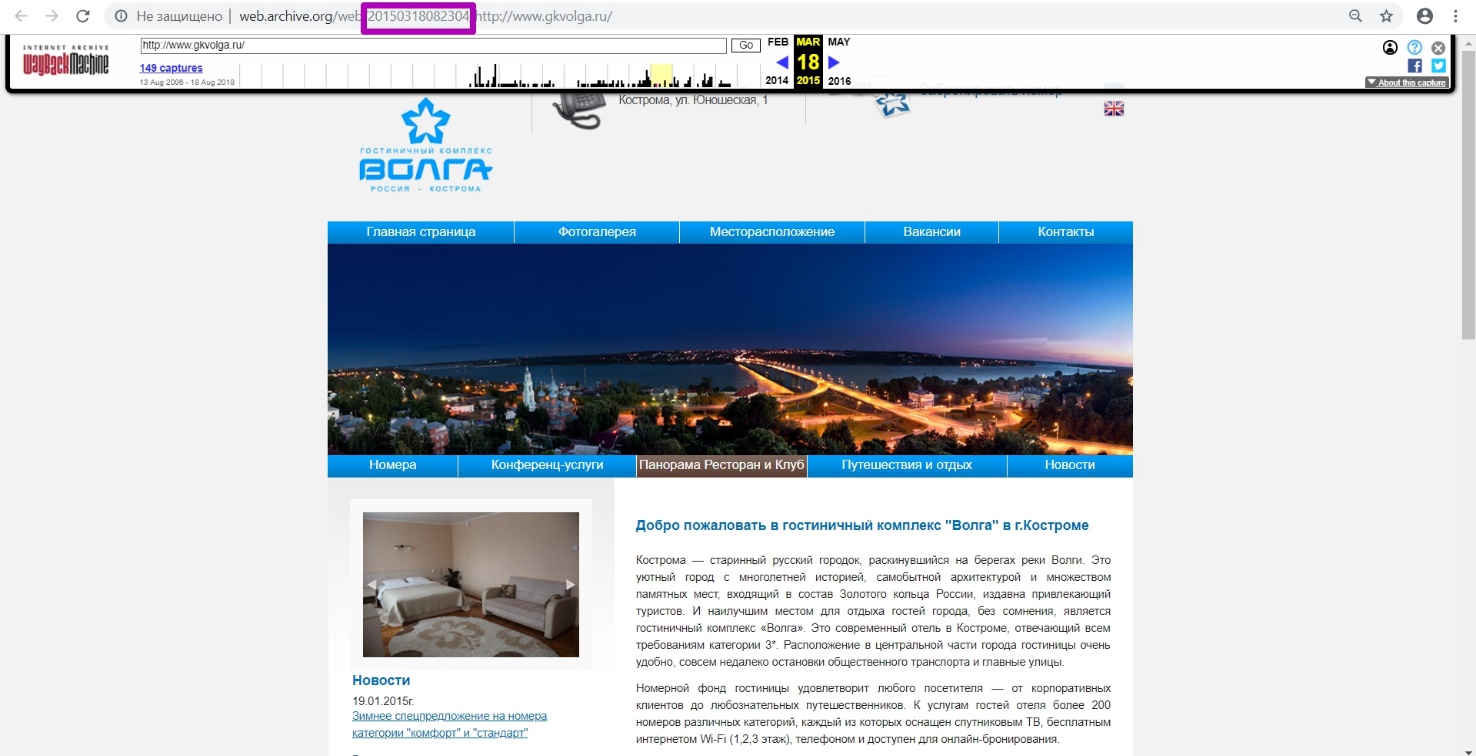
Once again select DevTools tool by clicking F12+F5 in the version we selected for March 18, 2015. As before, enter the domain name and by the method of date selecting we look for the period of the last unloading of the 200 response code. By month selection methods we see that March 2015 is the last period when website was available. Go to Summary tool. Now we open the 2015 supposed year.
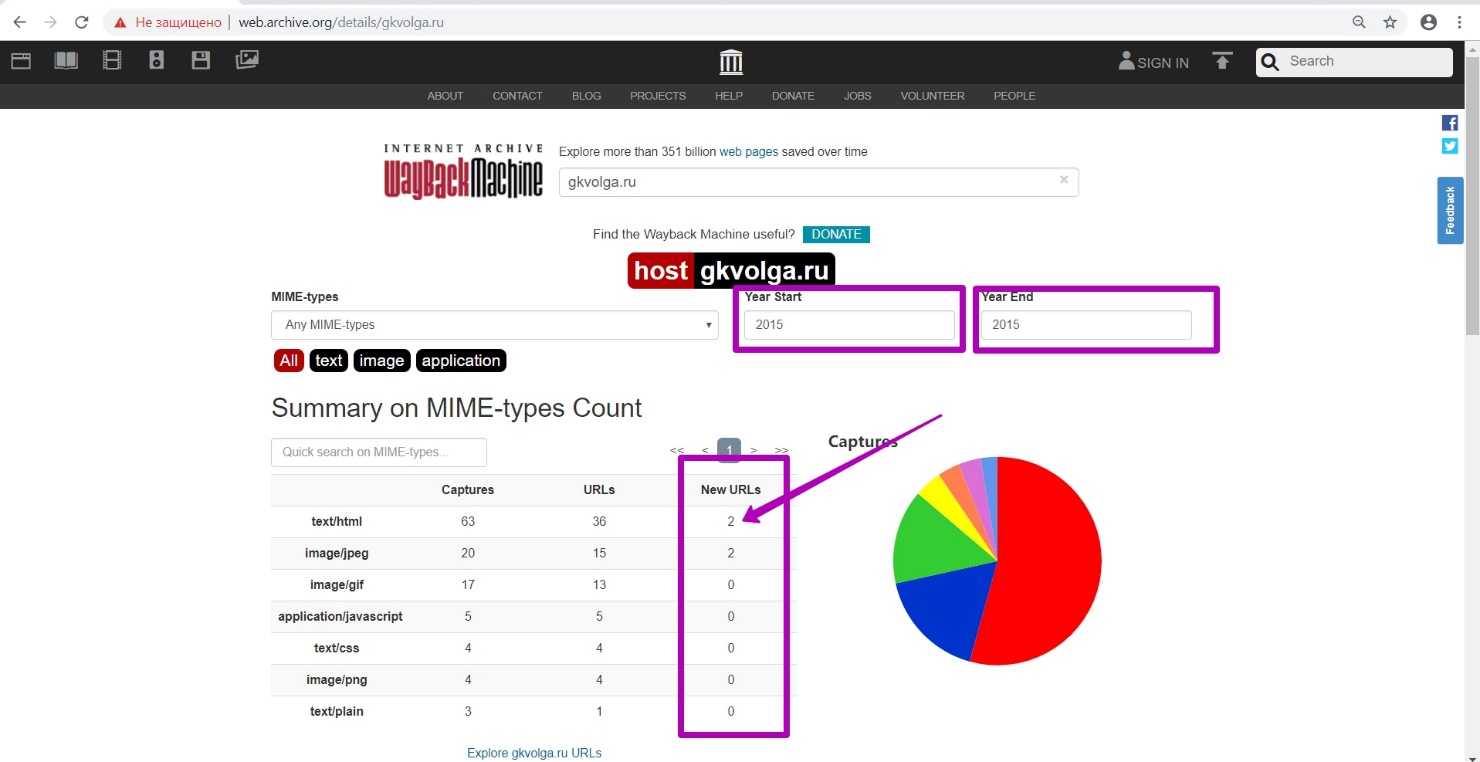
We see that during this period 2 new files were generated. If many files were created, we would look for them in April, May. But we will look for 2 files in the specified month by setting the “to” 201503 date.
In order to confirm our assumptions, open Explore tool (for 2015), and see that website data is no longer indexed (no table upload).
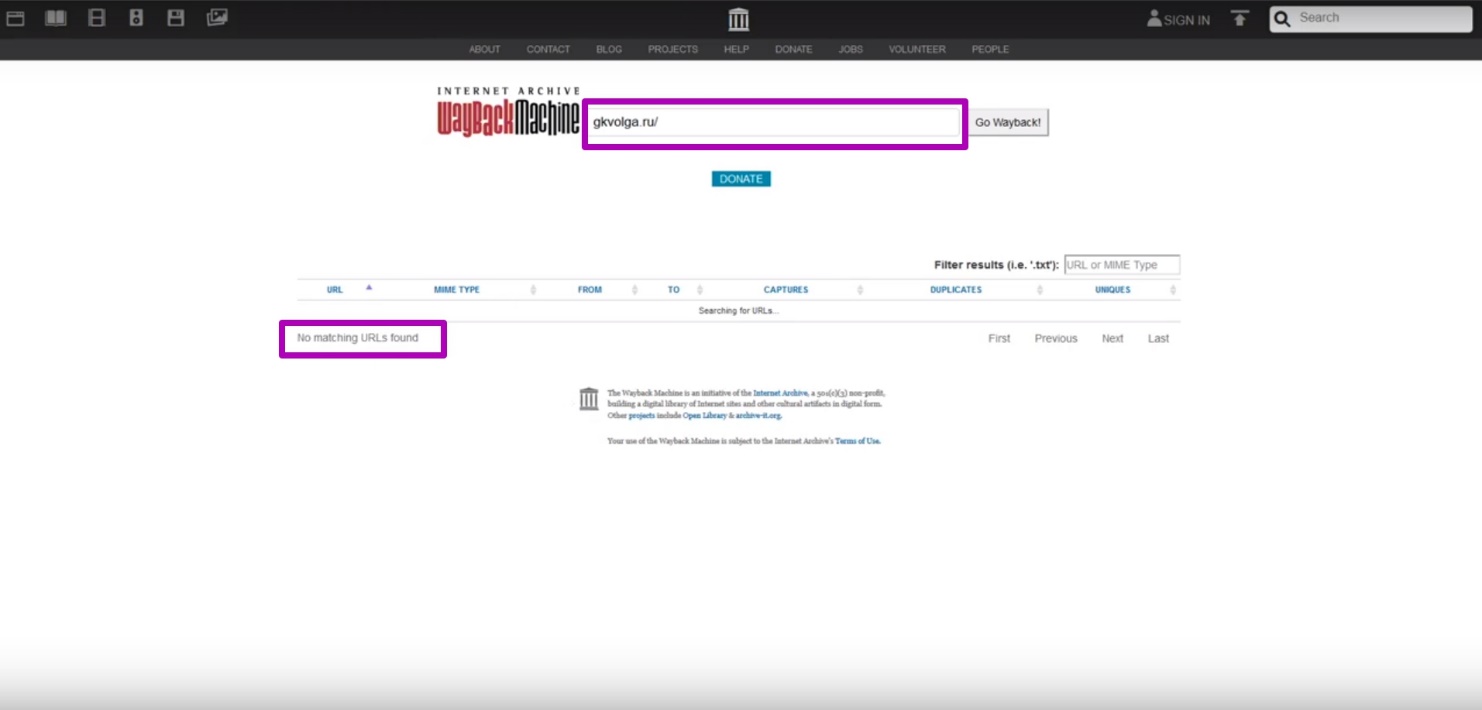
It means that robots.txt restrictions were configured on this website. We conclude that the date we determined is the last when the site was available.
How to restore websites from the Web Archive - archive.org. Part 1
How to restore websites from the Web Archive - archive.org. Part 2
The use of article materials is allowed only if the link to the source is posted: https://archivarix.com/en/blog/3-how-does-it-works-archiveorg/

Web Archive Interface: Instructions for the Summary, Explore, and Site map tools. For reference: Archive.org (Wayback Machine - Internet Archive) was created by Brewster Cale in 1996 about at the same…
In the previous article we examined archive.org operation, and in this article we will talk about a very important stage of site restoring from the Wayback Machine that relates to domain preparation f…
Choosing “BEFORE” limit when restoring websites from archive.org. When domain expires, domain provider or hoster’s parking page may appear. When entering such a page, the Internet Archive will save it…
- Full localization of Archivarix CMS into 13 languages (English, Spanish, Italian, German, French, Portuguese, Polish, Turkish, Japanese, Chinese, Russian, Ukrainian, Belarusian).
- Export all current site data to a zip archive to save a backup or transfer to another site.
- Show and remove broken zip archives in import tools.
- PHP version check during installation.
- Information for installing CMS on a server with NGINX + PHP-FPM.
- In the search, when the expert mode is on, the date/time of the page and a link to its copy in the WebArchive are displayed.
- Improvements to the user interface.
- Code optimization.
If you are a native speaker of a language into which our CMS has not yet been translated, then we invite you to make our product even better. Via Crowdin service you can apply and become our official translator into new languages.
- CLI support to deploy websites right from a command line, imports, settings, stats, history purge and system update.
- Support for password_hash() encrypted passwords that can be used in CLI.
- Expert mode to enable an additional debug information, experimental tools and direct links to WebArchive saved snapshots.
- Tools for broken internal images and links can now return a list of all missing urls instead of deleting.
- Import tool shows corrupted/incomplete zip files that can be removed.
- Improved cookie support to catch up with requirements of modern browsers.
- A setting to select default editor to HTML pages (visual editor or code).
- Changes tab showing text differences is off by default, can be turned on in settings.
- You can roll back to a specific change in the Changes tab.
- Fixed XML sitemap url for websites that are built with a www subdomain.
- Fixed removal temporary files that were created during an installation/import process.
- Faster history purge.
- Femoved unused localization phrases.
- Language switch on the login screen.
- Updated external packages to their most recent versions.
- Optimized memory usage for calculating text differences in the Changes tab.
- Improved support for old versions of php-dom extension.
- An experimental tool to fix file sizes in the database in case you edited files directly on a server.
- An experimental and very raw flat-structure export tool.
- An experimental public key support for the future API features.
- Fixed: History section did not work when there was no zip extension enabled in php.
- New History tab with details of changes when editing text files.
- .htaccess edit tool.
- Ability to clean up backups to the desired rollback point.
- "Missing URLs" section removed from Tools as it is accessible from the dashboard.
- Monitoring and showing free disk space in the dashboard.
- Improved check of the required PHP extensions on startup and initial installation.
- Minor cosmetic changes.
- All external tools updated to latest versions.
- Separate password for safe mode.
- Extended safe mode. Now you can create custom rules and files, but without executable code.
- Reinstalling the site from the CMS without having to manually delete anything from the server.
- Ability to sort custom rules.
- Improved Search & Replace for very large sites.
- Additional settings for the "Viewport meta tag" tool.
- Support for IDN domains on hosting with the old version of ICU.
- In the initial installation with a password, the ability to log out is added.
- If .htaccess is detected during integration with WP, then the Archivarix rules will be added to its beginning.
- When downloading sites by serial number, CDN is used to increase speed.
- Other minor improvements and fixes.
- New dashboard for viewing statistics, server settings and system updates.
- Ability to create templates and conveniently add new pages to the site.
- Integration with Wordpress and Joomla in one click.
- Now in Search & Replace, additional filtering is done in the form of a constructor, where you can add any number of rules.
- Now you can filter the results by domain/subdomains, date-time, file size.
- A new tool to reset the cache in Cloudlfare or enable / disable Dev Mode.
- A new tool for removing versioning in urls, for example, "?ver=1.2.3" in css or js. Allows you to repair even those pages that looked crooked in the WebArchive due to the lack of styles with different versions.
- The robots.txt tool has the ability to immediately enable and add a Sitemap map.
- Automatic and manual creation of rollback points for changes.
- Import can import templates.
- Saving/Importing settings of the loader contains the created custom files.
- For all actions that can last longer than a timeout, a progress bar is displayed.
- A tool to add a viewport meta tag to all pages of a site.
- Tools for removing broken links and images have the ability to account for files on the server.
- A new tool to fix incorrect urlencode links in html code. Rarely, but may come in handy.
- Improved missing urls tool. Together with the new loader, now counts calls to non-existent URLs.
- Regex Tips in Search & Replace.
- Improved checking for missing php extensions.
- Updated all used js tools to the latest versions.
This and many other cosmetic improvements and speed optimizations.