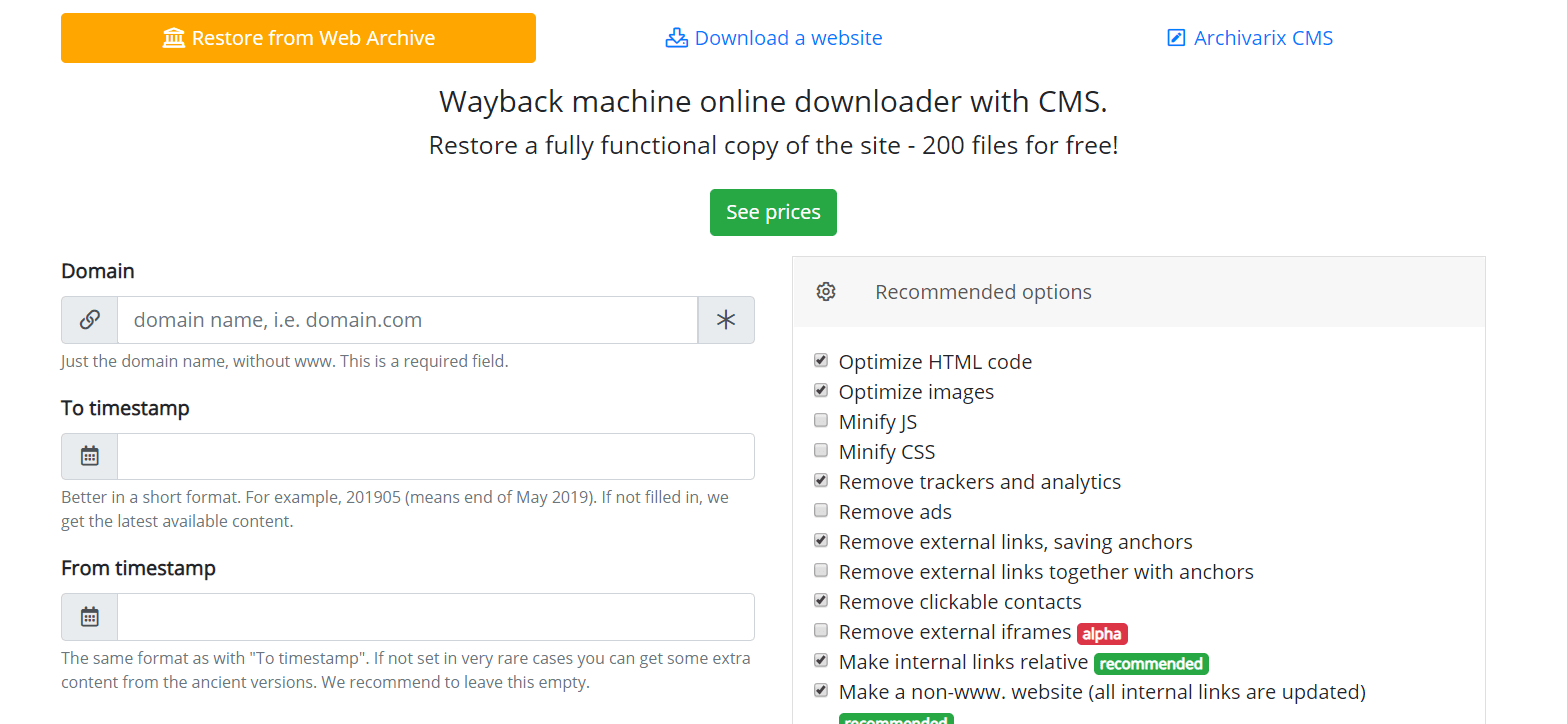
How does Archivarix work?
The Archivarix system is designed to download and restore sites that are no longer accessible from Web Archive, and those that are currently online. This is the main difference from the rest of “downloaders” and “site parsers”. Archivarix goal is not only to download, but also to restore the website in a form that it will be accessible on your server.
Let's start with the module that downloads websites from Web Archive. These are virtual servers located in California. Their location was chosen in such a way as to obtain the maximum possible connection speed with the Web Archive itself, because its servers are located in San Francisco. After entering data in the appropriate field on the module’s page https://en.archivarix.com/restore/, it takes a screenshot of the archived website and addresses the Web Archive API to request a list of files contained on the specified recovery date.
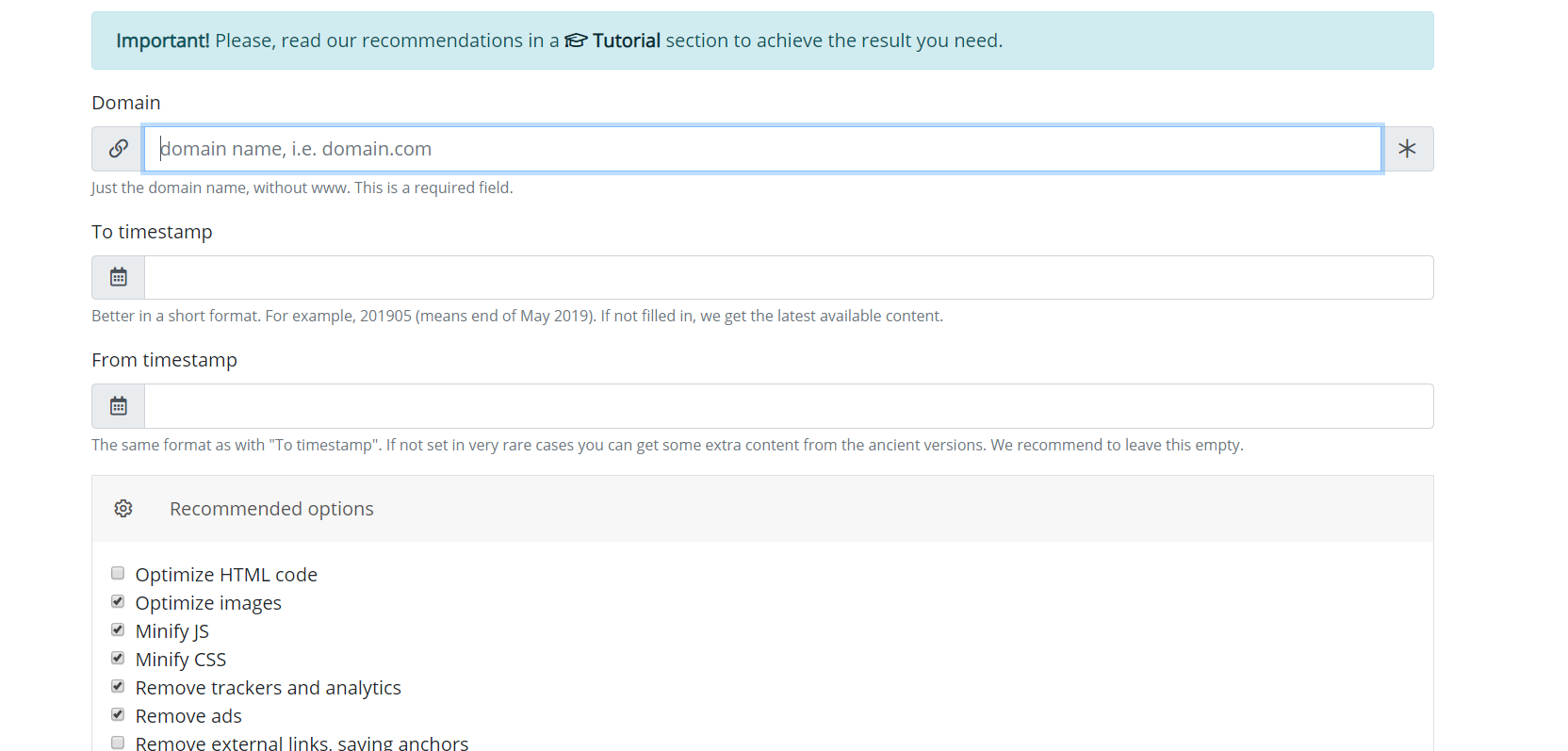
Having received a response to the request, the system generates a message with the analysis of the received data. User only needs to press the confirmation button in the received message in order to start downloading the website.
Using Web Archive API provides two advantages over direct downloading when the script simply follows the website’s links. First, all the files of this recovery are immediately known, you can estimate website volume and the time required to download it. Due to the nature of Web Archive operation, it sometimes works very unstable, so that connection breaks or incomplete download of files are possible, therefore module algorithm constantly checks the integrity of the received files and in such cases tries to download the content by reconnecting to the Web Archive server. Second, due to peculiarities of website indexing by Web Archive, not all website files may have direct links, which means that when you try to download a website simply by following the links, they will be unavailable. Therefore, restoration through the Web Archive API used by Archivarix, makes it possible to restore the maximum possible amount of archived website content for a specified date.
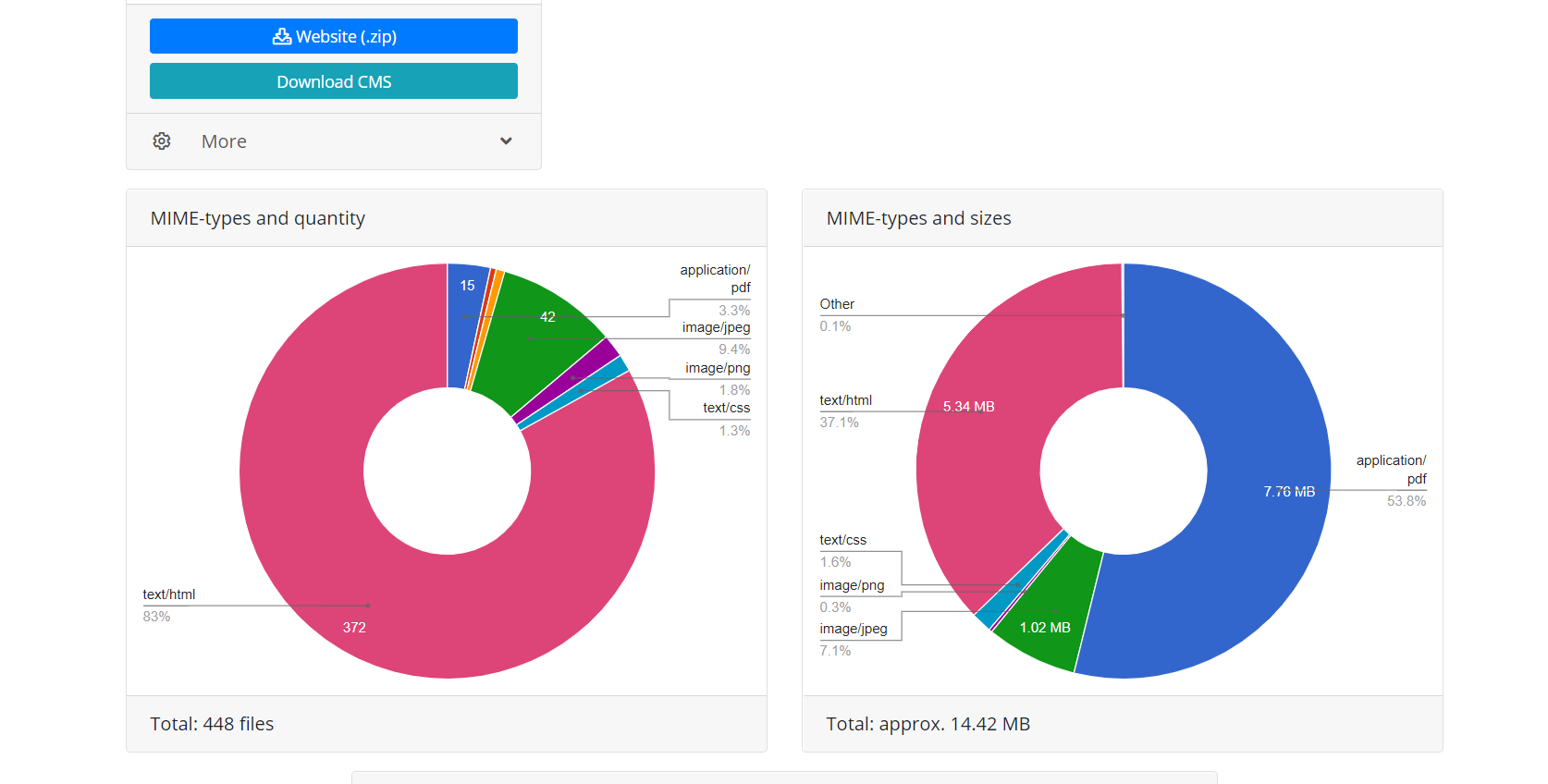
After completing the operation, the download module from the Web Archive transfers data to the processing module. It forms a website from the received files suitable for installation on Apache or Nginx server. Website operation is based on SQLite database, so to get started you just need to upload it to your server, and no installation of additional modules, MySQL databases and user creation is required. The processing module optimizes the website created; it includes image optimization, as well as CSS and JS compression. It may boost significantly the download speed of the restored website, if comparing to the original website. The download speed of some non-optimized Wordpress sites with a bunch of plugins and uncompressed media files may be significantly increased after processing by this module. It is obvious, that if website was optimized initially, this will not give a large increase in download speed.
Processing module removes advertising, counters and analytics by checking the received files against an extensive database of advertising and analytics providers. Removing external links and clickable contacts takes place simply by checksum code. In general, this algorithm carries out quite efficient cleaning the website of “traces of the previous owner”, although sometimes this does not exclude the need to manually correct something. For example, a self-written Java script redirecting website user to a certain monetization website will not be deleted by the algorithm. Sometimes you need to add missing pictures or remove unnecessary residues, as a spammed guestbook. Therefore, there is a need to hire an editor of the resulting website. And it already exists. Its name is Archivarix CMS.
This is a simple and compact CMS designed for editing websites created by the Archivarix system. It makes it possible to search and replace code throughout the website using regular expressions, editing the content in the WYSIWYG editor, add new pages and files. Archivarix CMS can be used together with any other CMS on one website.
Now let’s speak about other module used for downloading existing websites. Unlike the module for downloading websites from the Web Archive, it’s impossible to predict how many and which files you need to download, so the module’s servers work in a completely different way. Server spider simply follows all the links that are present on a website you are going to download. In order for the script not to fall into the endless download cycle of any auto-generated page, the maximum link depth is limited to ten clicks. And the maximum number of files that can be downloaded from the website must be specified in advance.
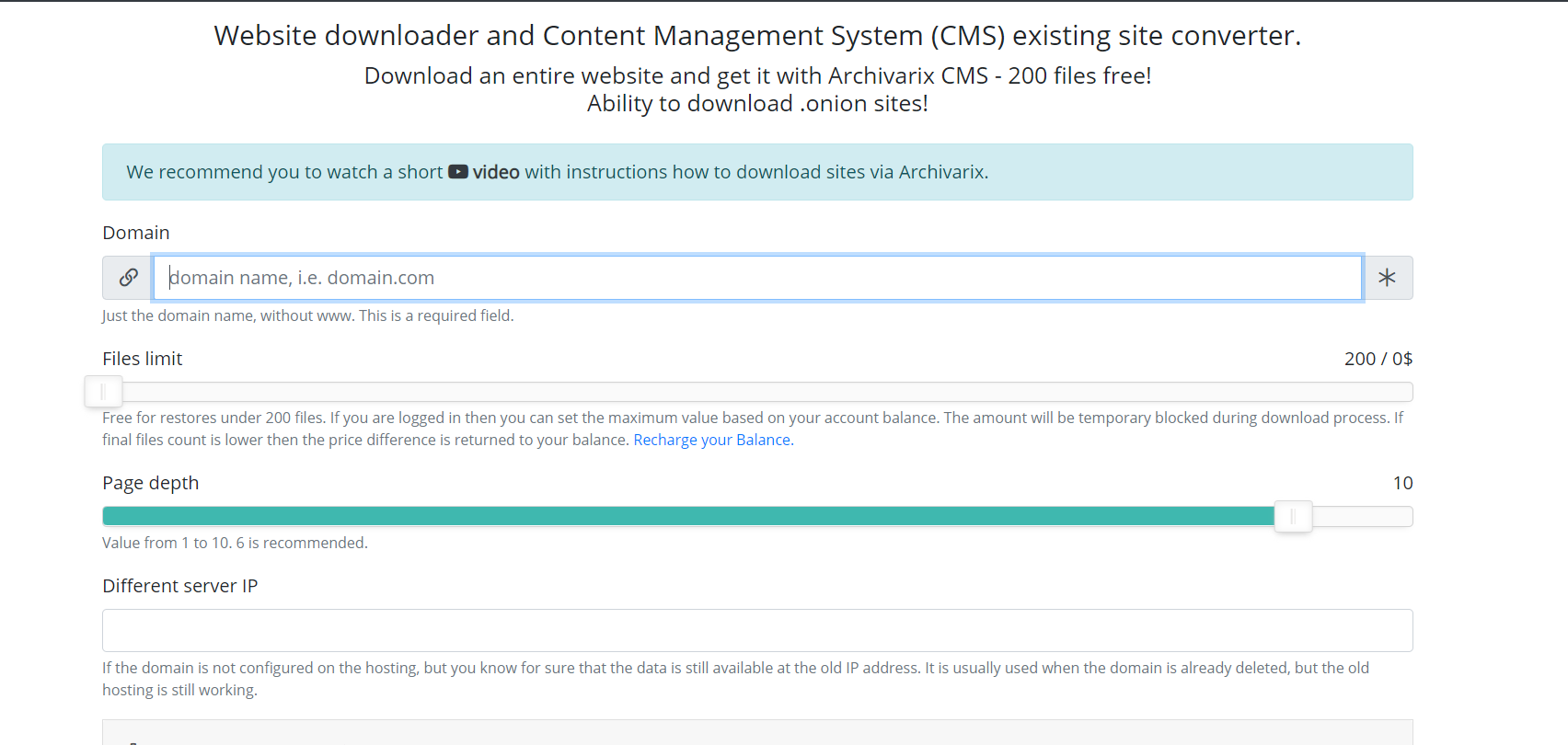
For the most complete downloading of the content that you need, there are several features that have been invented in this module. You can select a different User-Agent service spider, for example, Chrome Desktop or Googlebot. Referrer for cloaking bypass – if you need to download exactly what the user sees when logged in from the search, you can install a Google, Yandex, or other website referrer. In order to protect against banning by IP, you can choose to download the website using the Tor network, while the IP of the service spider changes randomly within this network. Other parameters, such as image optimization, ad removal and analytics are similar to the parameters of the download module from the Web Archive.
After the download is complete, the content is transferred to the processing module. Its operation principles are completely similar to the operation with the website downloaded from the Web Archive described above.
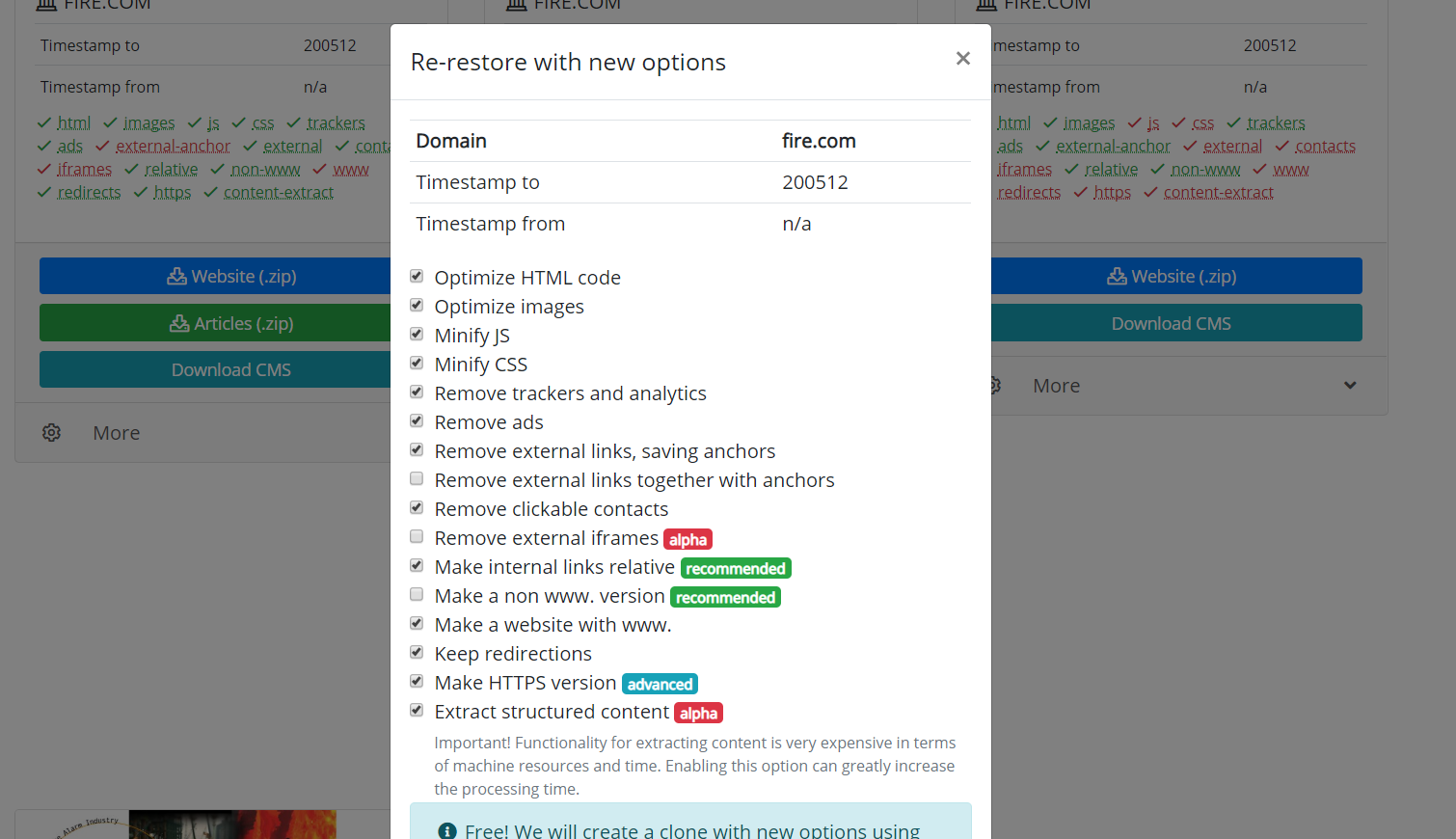
It is also worth mentioning the possibility to clone restored or downloaded websites. Sometimes it happens that during the recovery, one has chosen other parameters than it turned out to be necessary at the end. For example, removing external links was unnecessary, and some external links you needed, then you do not need to start downloading again. You just need to set new parameters on the recovery page and start re-creating the site.
The use of article materials is allowed only if the link to the source is posted: https://archivarix.com/en/blog/how-does-it-works/

The Archivarix system is designed to download and restore sites that are no longer accessible from Web Archive, and those that are currently online. This is the main difference from the rest of “downl…
By using the “Extract structured content” option you can easily make a Wordpress blog both from the site found on the Web Archive and from any other website. To do this, firstly find the source websit…
In order to make it convenient for you to edit the websites restored in our system, we have developed a simple Flat File CMS consisting of just one small php file. Despite its size, this CMS is a powe…
This article describes regular expressions used to search and replace content in websites restored using the Archivarix System. They are not unique to this system. If you know the regular expressions …
Our Website downloader system allows you to download up to 200 files from a website for free. If there are more files on the site and you need all of them, then you can pay for this service. Download …
- Full localization of Archivarix CMS into 13 languages (English, Spanish, Italian, German, French, Portuguese, Polish, Turkish, Japanese, Chinese, Russian, Ukrainian, Belarusian).
- Export all current site data to a zip archive to save a backup or transfer to another site.
- Show and remove broken zip archives in import tools.
- PHP version check during installation.
- Information for installing CMS on a server with NGINX + PHP-FPM.
- In the search, when the expert mode is on, the date/time of the page and a link to its copy in the WebArchive are displayed.
- Improvements to the user interface.
- Code optimization.
If you are a native speaker of a language into which our CMS has not yet been translated, then we invite you to make our product even better. Via Crowdin service you can apply and become our official translator into new languages.
- CLI support to deploy websites right from a command line, imports, settings, stats, history purge and system update.
- Support for password_hash() encrypted passwords that can be used in CLI.
- Expert mode to enable an additional debug information, experimental tools and direct links to WebArchive saved snapshots.
- Tools for broken internal images and links can now return a list of all missing urls instead of deleting.
- Import tool shows corrupted/incomplete zip files that can be removed.
- Improved cookie support to catch up with requirements of modern browsers.
- A setting to select default editor to HTML pages (visual editor or code).
- Changes tab showing text differences is off by default, can be turned on in settings.
- You can roll back to a specific change in the Changes tab.
- Fixed XML sitemap url for websites that are built with a www subdomain.
- Fixed removal temporary files that were created during an installation/import process.
- Faster history purge.
- Femoved unused localization phrases.
- Language switch on the login screen.
- Updated external packages to their most recent versions.
- Optimized memory usage for calculating text differences in the Changes tab.
- Improved support for old versions of php-dom extension.
- An experimental tool to fix file sizes in the database in case you edited files directly on a server.
- An experimental and very raw flat-structure export tool.
- An experimental public key support for the future API features.
- Fixed: History section did not work when there was no zip extension enabled in php.
- New History tab with details of changes when editing text files.
- .htaccess edit tool.
- Ability to clean up backups to the desired rollback point.
- "Missing URLs" section removed from Tools as it is accessible from the dashboard.
- Monitoring and showing free disk space in the dashboard.
- Improved check of the required PHP extensions on startup and initial installation.
- Minor cosmetic changes.
- All external tools updated to latest versions.
- Separate password for safe mode.
- Extended safe mode. Now you can create custom rules and files, but without executable code.
- Reinstalling the site from the CMS without having to manually delete anything from the server.
- Ability to sort custom rules.
- Improved Search & Replace for very large sites.
- Additional settings for the "Viewport meta tag" tool.
- Support for IDN domains on hosting with the old version of ICU.
- In the initial installation with a password, the ability to log out is added.
- If .htaccess is detected during integration with WP, then the Archivarix rules will be added to its beginning.
- When downloading sites by serial number, CDN is used to increase speed.
- Other minor improvements and fixes.
- New dashboard for viewing statistics, server settings and system updates.
- Ability to create templates and conveniently add new pages to the site.
- Integration with Wordpress and Joomla in one click.
- Now in Search & Replace, additional filtering is done in the form of a constructor, where you can add any number of rules.
- Now you can filter the results by domain/subdomains, date-time, file size.
- A new tool to reset the cache in Cloudlfare or enable / disable Dev Mode.
- A new tool for removing versioning in urls, for example, "?ver=1.2.3" in css or js. Allows you to repair even those pages that looked crooked in the WebArchive due to the lack of styles with different versions.
- The robots.txt tool has the ability to immediately enable and add a Sitemap map.
- Automatic and manual creation of rollback points for changes.
- Import can import templates.
- Saving/Importing settings of the loader contains the created custom files.
- For all actions that can last longer than a timeout, a progress bar is displayed.
- A tool to add a viewport meta tag to all pages of a site.
- Tools for removing broken links and images have the ability to account for files on the server.
- A new tool to fix incorrect urlencode links in html code. Rarely, but may come in handy.
- Improved missing urls tool. Together with the new loader, now counts calls to non-existent URLs.
- Regex Tips in Search & Replace.
- Improved checking for missing php extensions.
- Updated all used js tools to the latest versions.
This and many other cosmetic improvements and speed optimizations.